Unicode et bytes demystifiés
ℙƴ☂ℌøἤ
𝖀𝖓𝖎𝖈𝖔𝖉𝖊 🅔🅣 ⒪⒞⒯⒠⒯⒮ DΣMYƧƬIFIΣƧ
![]()
Boris FELD - PyConFR, Toulouse - 2017
Testons vos connaissances

Skeptical dog is skeptical

Les années 60

Apollo 11

Woodstock

Quelque chose important

Quelque chose d'énorme

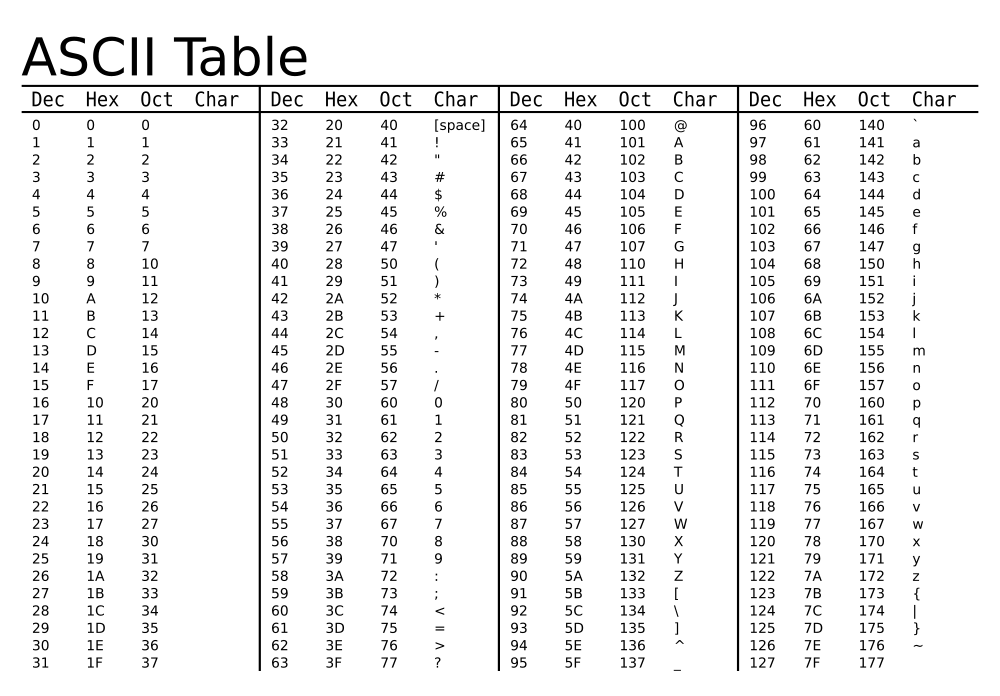
ASCII est né

La question à un millions de dollars
Dans les années 60, l'American Standards Association a voulu répondre à cette question:
Comment représenter du texte de manière numérique ?

Problème
Mais il y a un problème, les ordinateurs ne comprennents que le binaire. Comment transformer du texte en binaire ?

Everything is awesome...

... right?

Petit problème

L'anglais n'est pas universel 🌎 🌏
ASCII a résolu le problème pour les USA mais pas pour le reste du monde.

C'était le bazar

Une solution miracle !

Unicode contre ASCII
Vous vous rappellez la table ASCII ?

UTF-8 partout

Merci!
